
【はじめに】
こんにちは。23年卒SD部M.Kです。
前回投稿されました「機械学習part2:機械学習実践に向けて環境構築をしてみよう!」はお読みいただけたでしょうか?
まだお読みで無い方は、ぜひpart2から続けてお読みいただけると本投稿の内容がより分かりやすくなるかと思います!
また、機械学習の概要についてご説明している「機械学習part1:機械学習とは」も公開されております。お時間のある時にぜひお読みください!
前回のブログでは、機械学習の実践問題を行うための環境構築に関して理解いただけたかと思います。今回は環境構築がされている前提で、機械学習の中でも「決定木」というテーマについて、実践を交えつつ掘り下げていきます!
【目次】
- 復習
- 決定木の概要
- モデルの作成
- さいごに
【決定木の概要】
機械学習によるデータ分析では、設定した目的や現状の制約、モデルのメリットやデメリットを見極めたうえで、適切な学習手法(モデル)を選択する必要があります。そのモデルの1つに決定木モデルが存在します。
では、決定木モデルとは一体どんなモデルなのでしょうか。簡単に言ってしまえば、条件分岐によって分析する機械学習手法です。そして、分析結果を予測するためにフローチャートを作成しているのが特徴的です。
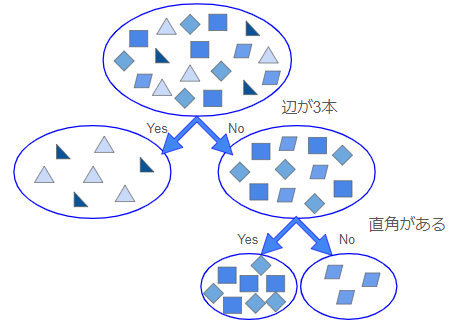
図のように、決定木は入力データの内容を基に条件分岐を繰り返しています。
ここで重要になるのは「どのような条件で分岐するのか」「何を基準に条件を選ぶのか」ということです。機械学習では、モデル自身の力で最適な条件を調べて決定木を作成しています。決定木はその条件で分類するにあたって「良い分類」か「悪い分類」かを判断する基準として、不純度という分類後における正解データの種類の比率を示す指標を使用しています。これは、小さいほど良いとされています。
ただし、コンピュータで考えられる全ての条件パターンを試して不純度を使用するには計算量が膨大になってしまうため、ランダムにある程度絞ったものだけで調べて効率化を図ります。
【モデルの作成】
決定木の概要が分かってきたところで、早速決定木モデルを作成していきましょう。(今回はモデルを作成する上で、須藤秋良著・『スッキリわかる機械学習入門』を参考にしています。)
まず始めに、モデルの作成にはscikit-learnというライブラリを使います。こちらは、さまざまなモジュールを含む分析モデルが提供されており、簡単に機械学習を実行できます。今回は決定木モデルを提供しているtreeモジュールを導入していきましょう。
# 決定木モデル treeモジュールのインポート
from sklearn import treeそして今回は、身長、体重、年齢を特徴量、犬派か猫派かを正解データとする独自に作成したデータを基に、モデルを学習させることにします。特徴量とは、分析対象データの中で予測の手掛かりとなる変数のことで、対象データの特徴を定量的な数値として表しています。先ほどのフローチャートでは、辺が3本かどうか、直角(90度の角)があるかどうか、が特徴量となります。
それでは、pandasという外部ライブラリを利用して、以下のCSVファイルを読み込んでいきます。

あらかじめCSVファイルは適切なフォルダに配置しておきましょう。今回はdatafilesというフォルダの中に配置しています。また、読み込みはread_csv関数を使っていきます。
# pandasをインポート import pandas as pd # CSVファイルを読み込んで、データフレームに変換 df = pd.read_csv('..\\datafiles\\dogsVScats.csv')
次に読み込んだデータを特徴量と正解データの2つに分類していきます。今回は、特徴量を変数xに、正解データを変数tに代入します。
# 特徴量の列を参照して、xに代入
xcol = ['身長','体重', '年齢']
x = df[xcol]
# 正解データを参照して、yに代入
y = df['好み']モデル学習前の事前準備は以上になります。
ここからは、treeモジュールにあるDecisionTreeClassifier関数を使って、これから学習するモデルの準備を行います。引数のrandom_stateでは、0以上の整数を指定して乱数を固定化します。そして、準備したモデルのfitメソッドに対して「特徴量」「正解データ」の変数をそれぞれ渡すことで、モデルは学習することができます。
# モデルの準備(未学習)
model = tree.DecisionTreeClassifier(random_state = 0)
# 学習の実行
model.fit(x, y)モデルを学習させたら、新しい特徴量をモデルに与えて予測してみましょう。身長170cm,、体重70kg、年齢20代の鈴木さんは犬派か猫派かどちらに分類されるでしょうか。予測するときは、predictメソッドを使います。このメソッドは、特徴量から予測した結果をarray型で返します。
# 身長170cm 体重70kg 年齢20代の鈴木さんのデータを2次元リストで作成
suzuki = [[170,70,20]]
#太郎がどちらに分類されるか予測
model.predict(suzuki)学習させたモデルがどれくらい予測精度が良いのかを調べる方法についても一緒に見てみましょう。複数件予測させて何%が正しかったかを示す比率を、正解率と言います。
正解率 = 実際の答えと予測結果が一致している件数 / 全データ件数
上記が正解率の定義で、パーセンテージが高いほど良い性能であることを表しています。そして正解率を出すためには、socreメソッドを使います。
# モデルの評価
model.score(x, y)最後に、学習させたモデルを今後再利用したい!改めてコードを書き直すのは面倒くさい!という方に必見です。モデルを保存する方法をご紹介します。保存しておきたい時は、Pythonの標準ライブラリであるpickleからdump関数を利用しましょう。引数の中で指定のファイル名を設定し、モデルをファイルに書き込みます。今回はInuNeko.pklというファイルに保存します。こちらはコードを書いているipynbファイルと同じ階層に作成されます。
# モデルの保存
import pickle
# モデルの保存
with open('InuNeko.pkl', 'wb') as file:
pickle.dump(model, file)ここまで記述したコードを一つにまとめたものが以下になります。
# 決定木モデル treeモジュールのインポート
from sklearn import tree
# モデルの保存
import pickle
# pandasをインポート
import pandas as pd
#関数のインポート
from sklearn.model_selection import train_test_split
# CSVファイルを読み込んで、データフレームに変換
df = pd.read_csv('..\\datafiles\\dogsVScats.csv')
# 特徴量の列を参照して、xに代入
xcol = ['身長','体重', '年齢']
x = df[xcol]
# 正解データを参照して、yに代入
y = df['好み']
# モデルの準備(未学習)
model = tree.DecisionTreeClassifier(random_state = 0)
# 学習の実行
model.fit(x, y)
# 身長170cm 体重70kg 年齢20代の鈴木さんのデータを2次元リストで作成
suzuki = [[170,70,20]]
#太郎がどちらに分類されるか予測
model.predict(suzuki)
# モデルの評価
model.score(x, y)
# モデルの保存
with open('InuNeko.pkl', 'wb') as file:
pickle.dump(model, file)【さいごに】
「機械学習part3:決定木について」はいかがだったでしょうか?
他のモデルについてはあまり触れられていませんが、視覚的にも分かりやすい決定木は、他の機械学習手法に比べても学びやすいのではないかと思います。また、今回は決定木の基本的な内容について触れましたが、突き詰めればもっとモデルの性能を高めたり等、まだまだできることは多くあります。もし興味を持たれた方がいらっしゃいましたら、ぜひ調べてみてください。
次回は機械学習編の最後、ランダムフォレストについて解説します。決定木を理解できているとランダムフォレストの理解も深まりますので、ぜひ一緒に学んで行きましょう!
最後までご覧いただきありがとうございました。

